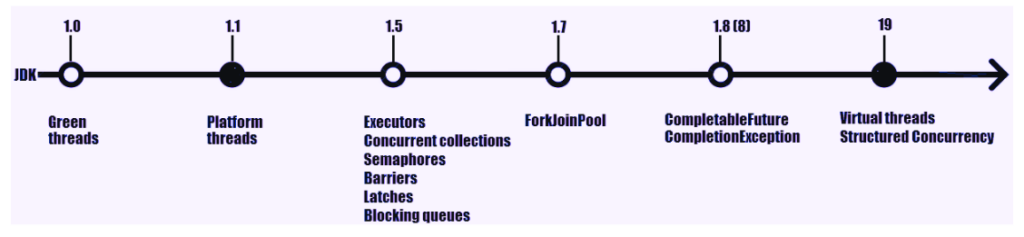
В Java виртуальные потоки( JEP-425 ) — это управляемые JVM легковесные потоки, которые помогают писать высокопроизводительные параллельные приложения(производительность означает, сколько единиц информации система может обработать за заданный промежуток времени).
В отличие от потоков платформы, виртуальные потоки не являются оболочками потоков ОС. Это легкие сущности Java(с собственной стековой памятью с небольшим объемом — всего несколько сотен байт), которые легко создавать, блокировать и уничтожать. Мы можем создавать их много одновременно(миллионы), чтобы они поддерживали огромную пропускную способность.
Виртуальные потоки хранятся в куче JVM(и они используют сборщик мусора) вместо стека ОС. Более того, виртуальные потоки планируются JVM через планировщик ForkJoinPool, перехватывающий работу. На практике JVM планирует и организует виртуальные потоки для запуска на потоках платформы таким образом, что поток платформы выполняет только один виртуальный поток за раз.
1. Традиционная модель потока и ее проблемы
Прежде чем углубляться в виртуальные потоки, давайте сначала разберемся, как работают потоки в традиционных потоках Java.
1.1. Классические/платформенные темы
В Java классический поток — это экземпляр класса java.lang.Thread. В дальнейшем мы также будем называть их потоками платформы.
Традиционно Java рассматривала потоки платформы как тонкие обертки вокруг потоков операционной системы(ОС). Создание таких потоков платформы всегда было затратным(из-за большого стека и других ресурсов, которые поддерживаются операционной системой), поэтому Java использовала пулы потоков, чтобы избежать накладных расходов при создании потоков.
Количество потоков платформы также должно быть ограничено, поскольку эти ресурсоемкие потоки могут повлиять на производительность всей машины. Это в основном связано с тем, что потоки платформы сопоставляются 1:1 с потоками ОС.
1.2 Проблемы масштабируемости потоков платформы
Потоки платформы всегда было легко моделировать, программировать и отлаживать, поскольку они используют единицу параллелизма платформы для представления единицы параллелизма приложения. Это называется шаблоном потока на запрос.
Однако этот шаблон ограничивает пропускную способность сервера, поскольку количество одновременных запросов(которые может обработать сервер) становится прямо пропорциональным производительности оборудования сервера. Таким образом, количество доступных потоков должно быть ограничено даже в многоядерных процессорах.
Помимо количества потоков, задержка также является большой проблемой. Если вы внимательно посмотрите, в современном мире микросервисов запрос обслуживается путем извлечения/обновления данных на нескольких системах и серверах. Пока приложение ждет информацию от других серверов, текущий поток платформы остается в состоянии ожидания. Это пустая трата вычислительных ресурсов и серьезное препятствие для достижения высокой пропускной способности приложения.
1.3 Проблемы реактивного программирования
Реактивное программирование решило проблему потоков платформы, ожидающих ответов от других систем. Асинхронные API не ждут ответа, а работают через обратные вызовы. Всякий раз, когда поток вызывает асинхронный API, поток платформы возвращается в пул до тех пор, пока не придет ответ от удаленной системы или базы данных. Позже, когда ответ придет, JVM выделит другой поток из пула, который обработает ответ и так далее. Таким образом, в обработке одного асинхронного запроса участвуют несколько потоков.
В асинхронном программировании задержка устраняется, но количество потоков платформы все еще ограничено из-за ограничений оборудования, поэтому у нас есть предел масштабируемости. Другая большая проблема заключается в том, что такие асинхронные программы выполняются в разных потоках, поэтому их очень сложно отлаживать или профилировать.
Также нам придется принять новый стиль программирования, далекий от типичных циклов и условных операторов. Новый синтаксис в стиле лямбда затрудняет понимание существующего кода и написание программ, поскольку теперь нам придется разбить нашу программу на несколько более мелких единиц, которые могут выполняться независимо и асинхронно.
Таким образом, можно сказать, что виртуальные потоки также улучшают качество кода, адаптируя традиционный синтаксис и используя преимущества реактивного программирования.
2. Виртуальные потоки выглядят многообещающе
Подобно традиционным потокам, виртуальный поток также является экземпляром java.lang.Thread, который запускает свой код в базовом потоке ОС, но он не блокирует поток ОС на весь срок жизни кода. Поддержание потоков ОС свободными означает, что многие виртуальные потоки могут запускать свой код Java в одном и том же потоке ОС, эффективно разделяя его.
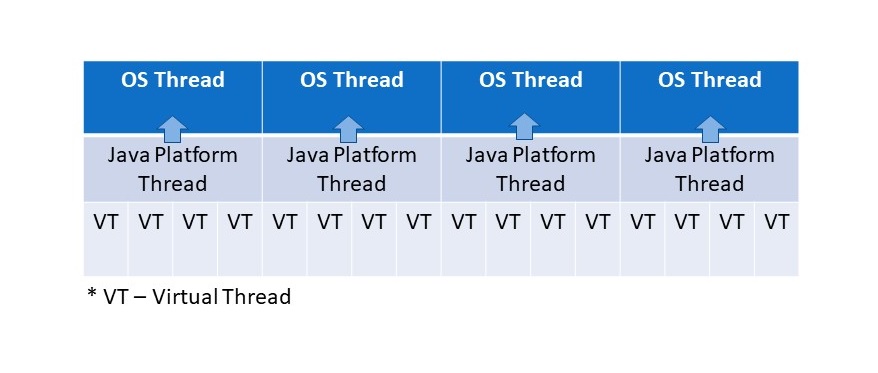
Стоит отметить, что мы можем создать очень большое количество виртуальных потоков(миллионы) в приложении, не завися от количества потоков платформы. Эти виртуальные потоки управляются JVM, поэтому они не добавляют дополнительных накладных расходов на переключение контекста, поскольку они хранятся в оперативной памяти как обычные объекты Java.
Подобно традиционным потокам, код приложения выполняется в виртуальном потоке на протяжении всего запроса(в стиле «поток на запрос»), но виртуальный поток потребляет поток ОС только тогда, когда он выполняет вычисления на ЦП. Они не блокируют поток ОС, пока они ждут или спят.
Виртуальные потоки помогают достичь той же высокой масштабируемости и пропускной способности, что и асинхронные API, с той же конфигурацией оборудования, не добавляя при этом сложности синтаксиса.
Виртуальные потоки лучше всего подходят для выполнения кода, который большую часть времени проводит в заблокированном состоянии, например, ожидая поступления данных на сетевой сокет или элемента в очереди.
3. Разница между потоками платформы и виртуальными потоками
- Виртуальные потоки всегда являются потоками-демонами. Метод Thread.setDaemon(false) не может изменить виртуальный поток так, чтобы он стал потоком не-демон. Обратите внимание, что JVM завершается, когда все запущенные потоки не-демон завершены. Это означает, что JVM не будет ждать завершения виртуальных потоков перед выходом.
Thread virtualThread = ...; //Create virtual thread//virtualThread.setDaemon(true); //It has no effect
- Виртуальные потоки всегда имеют нормальный приоритет, и приоритет не может быть изменен, даже с помощью метода setPriority(n). Вызов этого метода в виртуальном потоке не имеет никакого эффекта.
Thread virtualThread = ...; //Create virtual thread//virtualThread.setPriority(Thread.MAX_PRIORITY); //It has no effect
- Виртуальные потоки не являются активными членами групп потоков. При вызове в виртуальном потоке Thread.getThreadGroup() возвращает группу потоков-заполнителей с именем «VirtualThreads».
- Виртуальные потоки не поддерживают методы stop(), suspend() или resume(). Эти методы выдают исключение UnsupportedOperationException при вызове в виртуальном потоке.
4. Сравнение производительности потоков платформы и виртуальных потоков
Давайте разберемся в разнице между двумя типами потоков, когда они представлены с одним и тем же исполняемым кодом.
Для демонстрации у нас есть очень простая задача, которая ждет 1 секунду перед тем, как вывести сообщение в консоль. Мы создаем эту задачу, чтобы сделать пример простым и сосредоточиться на концепции.
final AtomicInteger atomicInteger = new AtomicInteger();Runnable runnable =() -> {try {Thread.sleep(Duration.ofSeconds(1));} catch(Exception e) {System.out.println(e);}System.out.println("Work Done - " + atomicInteger.incrementAndGet());};Теперь мы создадим 10 000 потоков из этого Runnable и выполним их с помощью виртуальных потоков и потоков платформы, чтобы сравнить производительность обоих. Мы будем использовать API Duration.between() для измерения прошедшего времени выполнения всех задач.
Во-первых, мы используем пул из 100 потоков платформы. Таким образом, Executor сможет запускать 100 задач одновременно, а другим задачам придется подождать. Поскольку у нас 10 000 задач, общее время завершения выполнения составит примерно 100 секунд.
Instant start = Instant.now();try(var executor = Executors.newFixedThreadPool(100)) {for(int i = 0; i < 10_000; i++) {executor.submit(runnable);}}Instant finish = Instant.now();long timeElapsed = Duration.between(start, finish).toMillis();System.out.println("Total elapsed time : " + timeElapsed); Общее прошедшее время: 101152 //Приблизительно 101 секунда
На сегодняшний день виртуальные потоки являются предварительным API и отключены по умолчанию. Используйте $ java —source 19 —enable-preview Main.java для запуска кода.
Далее мы заменим Executors.newFixedThreadPool(100) на Executors.newVirtualThreadPerTaskExecutor(). Это позволит выполнять все задачи в виртуальных потоках вместо потоков платформы.
Instant start = Instant.now();try(var executor = Executors.newVirtualThreadPerTaskExecutor()) {for(int i = 0; i < 10_000; i++) {executor.submit(runnable);}}Instant finish = Instant.now();long timeElapsed = Duration.between(start, finish).toMillis();System.out.println("Total elapsed time : " + timeElapsed); Общее прошедшее время: 1589 //Приблизительно 1,5 секунды
Обратите внимание на невероятно высокую производительность виртуальных потоков, которые сократили время выполнения со 100 секунд до 1,5 секунд без каких-либо изменений в исполняемом коде.
5. Как создавать виртуальные потоки
С точки зрения API виртуальный поток — это еще одна разновидность java.lang.Thread. Если мы немного углубимся в getClass(), то увидим, что класс виртуального потока — это java.lang.VirtualThread, который является конечным непубличным классом, расширяющим класс BaseVirtualThread, который является запечатанным абстрактным классом, расширяющим java.lang.Thread.
final class VirtualThread extends BaseVirtualThread {…}sealed abstract class BaseVirtualThread extends Threadpermits VirtualThread, ThreadBuilders.BoundVirtualThread {…}5.1 Использование Thread.startVirtualThread()
Мы можем создать и запустить виртуальный поток для нашей задачи через startVirtualThread(Runnable task). Этот метод создает новый виртуальный поток для выполнения заданной Runnable задачи и планирует ее выполнение.
Runnable runnable =() -> System.out.println("Inside Runnable"); // Task to runThread vThread = Thread.startVirtualThread(runnable);//orThread vThread = Thread.startVirtualThread(() -> {//Code to execute in virtual threadSystem.out.println("Inside Runnable");});5.2 Использование Thread.Builder
Если мы хотим явно запустить поток после его создания, мы можем использовать Thread.ofVirtual(), который возвращает экземпляр VirtualThreadBuilder. Его метод start() запускает виртуальный поток.
Стоит отметить, что Thread.ofVirtual().start(runnable) эквивалентен Thread.startVirtualThread(runnable).
Runnable runnable =() -> System.out.println("Inside Runnable");Thread virtualThread = Thread.ofVirtual().start(runnable);Мы можем использовать ссылку Thread.Builder для создания и запуска нескольких потоков.
Runnable runnable =() -> System.out.println("Inside Runnable");Thread.Builder builder = Thread.ofVirtual().name("JVM-Thread");Thread t1 = builder.start(runnable);Thread t2 = builder.start(runnable);Аналогичный API Thread.ofPlatform() также существует для создания потоков платформы.
Thread.Builder builder = Thread.ofPlatform().name("Platform-Thread");Thread t1 = builder.start(() -> {...});Thread t2 = builder.start(() -> {...});5.3 Использование Executors.newVirtualThreadPerTaskExecutor()
Этот метод создает один новый виртуальный поток на задачу. Количество потоков, создаваемых Executor, не ограничено.
В следующем примере мы отправляем 10 000 задач и ждем их завершения. Код создаст 10 000 виртуальных потоков для завершения этих 10 000 задач.
Обратите внимание, что следующий синтаксис является частью структурированного параллелизма, еще одной новой функции, предложенной в Project Loom. Мы обсудим это в отдельном посте.
try(var executor = Executors.newVirtualThreadPerTaskExecutor()) {IntStream.range(0, 10_000).forEach(i -> {executor.submit(() -> {Thread.sleep(Duration.ofSeconds(1));return i;});});}6. Создание не запущенного виртуального потока
Создание незапущенного виртуального потока можно выполнить с помощью unstarted(Runnable task) следующим образом:
Thread vThread = Thread.ofVirtual().unstarted(task);
Или через Thread.Builder следующим образом:
Thread.Builder builder = Thread.ofVirtual();Thread vThread = builder.unstarted(task);
На этот раз поток не запланирован для выполнения. Он будет запланирован для выполнения только после того, как мы явно вызовем метод start():
vThread.start();
Обратите внимание, что метод unstarted() также доступен для потоков платформы через метод Thread.ofPlatform().unstarted(task).
7. Ожидание завершения виртуального потока
Виртуальный поток всегда работает как поток-демон. Когда заданная задача выполняется виртуальным потоком, основной поток не блокируется. Чтобы дождаться завершения виртуального потока, нам нужно вызвать один из методов join().
Когда мы используем join() без аргументов, то он ждет бесконечно. Используйте join(Duration duration) или join(long millis) для ожидания с ограничением по времени. Эти методы выдают InterruptedException, поэтому вам нужно перехватить его и обработать или просто выдать.
vThread.join();
Теперь, из-за join(), основной поток не может завершиться раньше виртуального потока. Он должен ждать, пока виртуальный поток завершится.
8. Лучшие практики, которым стоит следовать
Прежде чем изучать лучшие практики, четко дайте понять, что виртуальные потоки НЕ быстрее, чем потоки платформы, и они не повышают вычислительные возможности в памяти. Однако виртуальные потоки могут запускаться гораздо быстрее, чем потоки платформы.
Еще один момент, который следует запомнить: виртуальные потоки НЕ освобождают задачу. Виртуальный поток принимает задачу и должен вернуть результат, иначе он будет прерван.
8.1. НЕ объединяйте виртуальные потоки
Пул потоков Java был разработан, чтобы избежать накладных расходов на создание новых потоков ОС, поскольку их создание было дорогостоящей операцией. Но создание виртуальных потоков не требует больших затрат, поэтому никогда не возникает необходимости в их пуле. Рекомендуется создавать новый виртуальный поток каждый раз, когда он нам нужен.
Обратите внимание, что после использования виртуальных потоков наше приложение может обрабатывать миллионы потоков, но другие системы или платформы обрабатывают только несколько запросов за раз. Например, у нас может быть только несколько подключений к базе данных или сетевых подключений к другим серверам.
В этих случаях также не используйте пул потоков. Вместо этого используйте семафоры, чтобы убедиться, что только определенное количество потоков обращается к этому ресурсу.
private static final Semaphore SEMAPHORE = new Semaphore(50);SEMAPHORE.acquire();try {// semaphore limits to 50 concurrent access requests//Access the database or resource} finally {SEMAPHORE.release();}8.2 Избегайте использования локальных переменных потока
Виртуальные потоки поддерживают локальное поведение потока так же, как и потоки платформы, но поскольку виртуальных потоков можно создавать миллионами, локальные переменные потока следует использовать только после тщательного обдумывания.
Например, если мы масштабируем миллион виртуальных потоков в приложении, то будет миллион экземпляров ThreadLocal вместе с данными, на которые они ссылаются. Такое большое количество экземпляров может оказать достаточную нагрузку на физическую память, и этого следует избегать.
Переменные Extent-Local [JEP-429] являются лучшей альтернативой. Обратите внимание, что в Java 21 [ JEP-444 ] виртуальные потоки теперь поддерживают локальные переменные потока все время. Больше невозможно, как это было в предварительных выпусках, создавать виртуальные потоки, которые не могут иметь локальные переменные потока.
8.3. Используйте ReentrantLock вместо синхронизированных блоков
Существует два конкретных сценария, в которых виртуальный поток может блокировать поток платформы(это называется закреплением потоков ОС).
- Когда он выполняет код внутри синхронизированного блока или метода, или
- Когда он выполняет собственный метод или стороннюю функцию.
Такой синхронизированный блок не делает приложение некорректным, но ограничивает масштабируемость приложения аналогично потокам платформы.
Если метод используется очень часто и использует синхронизированный блок, рекомендуется рассмотреть возможность его замены на механизм ReentrantLock.
Поэтому вместо использования синхронизированного блока, подобного этому:
public synchronized void m() {try {// ... access resource} finally {//}}используйте ReentrantLock следующим образом:
private final ReentrantLock lock = new ReentrantLock();public void m() {lock.lock(); // block until condition holdstry {// ... access resource} finally {lock.unlock();}}Предполагается, что нет необходимости заменять синхронизированные блоки и методы, которые используются нечасто(например, выполняются только при запуске) или защищают операции в памяти.
9. Заключение
Традиционные потоки Java служили очень хорошо в течение длительного времени. С растущим спросом на масштабируемость и высокую пропускную способность в мире микросервисов виртуальные потоки станут важной вехой в истории Java.
С помощью виртуального потока программа может обрабатывать миллионы потоков с небольшим объемом физической памяти и вычислительных ресурсов, что в противном случае было бы невозможно с традиционными потоками платформы. Это также приведет к лучше написанным программам в сочетании со структурированным параллелизмом.