В этом уроке по парсеру XML Java вы научитесь читать XML с помощью парсера DOM. Парсер DOM предназначен для работы с XML как с объектным графом(древовидной структурой) в памяти — так называемой «Объектной моделью документа(DOM)».
Сначала парсер обходит входной XML-файл и создает объекты DOM, соответствующие узлам в XML-файле. Эти объекты DOM связаны между собой в древовидную структуру. Как только парсер завершает процесс разбора, мы получаем из него эту древовидную структуру объекта DOM. Теперь мы можем обходить структуру DOM вперед и назад, как нам нужно — получать/обновлять/удалять данные из нее.
Другими возможными способами чтения XML-файла являются также использование парсера SAX и парсера StAX.
1. Настройка
В демонстрационных целях мы проанализируем приведенный ниже XML-файл во всех примерах кода.
<сотрудники><сотрудник id="111"><имя>Локеш</имя><фамилия>Гупта</фамилия><местоположение>Индия</местоположение></сотрудник><сотрудник id="222"><имя>Алекс</имя><фамилия>Гуссин</фамилия><местоположение>Россия</местоположение></сотрудник><сотрудник id="333"><имя>Дэвид</имя><фамилия>Физор</фамилия><местоположение>США</местоположение></сотрудник></сотрудники>
2. API парсера DOM
Давайте рассмотрим несколько основных шагов по созданию и использованию DOM-парсера для анализа XML-файла в Java.
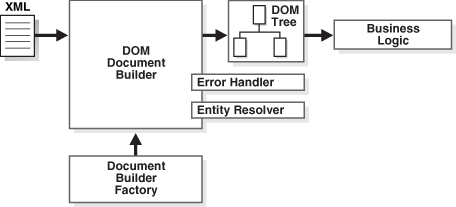
1.1 Импорт пакетов парсера dom
Сначала нам нужно будет импортировать пакеты парсера DOM в наше приложение.
import org.w3c.dom.*;import javax.xml.parsers.*;import java.io.*;
1.2. Создать DocumentBuilder
Следующим шагом будет создание объекта DocumentBuilder.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();
1.3. Создание объекта Document из XML-файла
Прочитать XML-файл в объект Document.
Document document = builder.parse(new File( file ));
1.4.Проверка структуры документа
Проверка XML необязательна, но ее лучше провести перед началом анализа.
Schema schema = null;try {String language = XMLConstants.W3C_XML_SCHEMA_NS_URI;SchemaFactory factory = SchemaFactory.newInstance(language);schema = factory.newSchema(new File(name));} catch(Exception e) {e.printStackStrace();}Validator validator = schema.newValidator();validator.validate(new DOMSource(document));1.5 Извлечение корневого элемента
Мы можем получить корневой элемент из XML-документа, используя приведенный ниже код.
Element root = document.getDocumentElement();
1.6.Изучите атрибуты
Мы можем проверить атрибуты XML-элемента, используя следующие методы.
element.getAttribute("attributeName") ; //returns specific attributeelement.getAttributes(); //returns a Map(table) of names/values1.7.Исследование дочерних элементов
Дочерние элементы для указанного узла можно запросить следующим образом.
node.getElementsByTagName("subElementName"); //returns a list of sub-elements of specified namenode.getChildNodes(); //returns a list of all child nodes2. Чтение XML-файла с помощью DOM-парсера
В приведенном ниже примере кода мы предполагаем, что пользователь уже знает структуру файла employees.xml(его узлы и атрибуты). Поэтому пример напрямую начинает извлекать информацию и выводить ее на консоль. В реальном приложении мы будем использовать эту информацию для какой-то реальной цели, а не просто выводить ее на консоль и уходить.
public static Document readXMLDocumentFromFile(String fileNameWithPath) throws Exception {//Get Document BuilderDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();//Build DocumentDocument document = builder.parse(new File(fileNameWithPath));//Normalize the XML Structure; It's just too important !!document.getDocumentElement().normalize();return document;}Теперь мы можем использовать этот метод для анализа XML-файла и проверки его содержимого.
public static void main(String[] args) throws Exception {Document document = readXMLDocumentFromFile("c:/temp/employees.xml");//Verify XML Content//Here comes the root nodeElement root = document.getDocumentElement();System.out.println(root.getNodeName());//Get all employeesNodeList nList = document.getElementsByTagName("employee");System.out.println("============================");for(int temp = 0; temp < nList.getLength(); temp++) {Node node = nList.item(temp);if(node.getNodeType() == Node.ELEMENT_NODE) {//Print each employee's detailElement eElement =(Element) node;System.out.println("\nEmployee id : " + eElement.getAttribute("id"));System.out.println("First Name : " + eElement.getElementsByTagName("firstName").item(0).getTextContent());System.out.println("Last Name : " + eElement.getElementsByTagName("lastName").item(0).getTextContent());System.out.println("Location : " + eElement.getElementsByTagName("location").item(0).getTextContent());}}}Вывод программы:
employees============================Employee id : 111First Name : LokeshLast Name : GuptaLocation : IndiaEmployee id : 222First Name : AlexLast Name : GussinLocation : RussiaEmployee id : 333First Name : DavidLast Name : FeezorLocation : USA
3. Считывание XML в POJO
Другим требованием реального приложения может быть заполнение объектов DTO информацией, извлеченной в приведенном выше примере кода. Я написал простую программу, чтобы помочь нам понять, как это можно легко сделать.
Допустим, нам нужно заполнить объекты Employee, которые определены следующим образом.
public class Employee {private Integer id;private String firstName;private String lastName;private String location;//Setters, Getters and toString()}Теперь взгляните на пример кода для заполнения списка объектов Employee. Это так же просто, как вставить несколько строк между кодом, а затем скопировать значения в DTO вместо консоли.
public static List<Employee> parseXmlToPOJO(String fileName) throws Exception {List<Employee> employees = new ArrayList<Employee>();DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document document = builder.parse(new File(fileName));document.getDocumentElement().normalize();NodeList nList = document.getElementsByTagName("employee");for(int temp = 0; temp < nList.getLength(); temp++) {Node node = nList.item(temp);if(node.getNodeType() == Node.ELEMENT_NODE) {Element eElement =(Element) node;Employee employee = new Employee();employee.setId(Integer.parseInt(eElement.getAttribute("id")));employee.setFirstName(eElement.getElementsByTagName("firstName").item(0).getTextContent());employee.setLastName(eElement.getElementsByTagName("lastName").item(0).getTextContent());employee.setLocation(eElement.getElementsByTagName("location").item(0).getTextContent());//Add Employee to listemployees.add(employee);}}return employees;}4. Анализ «неизвестного» XML с помощью NamedNodeMap
Предыдущий пример показывает, как мы можем итерировать по XML-документу, проанализированному с известной или малоизвестной вам структурой, пока вы пишете код. В некоторых случаях нам, возможно, придется писать код таким образом, что даже если есть некоторые различия в предполагаемой XML-структуре во время кодирования, программа должна работать без сбоев.
Здесь мы перебираем все элементы, присутствующие в дереве XML-документа. Мы можем добавить наши знания и изменить код таким образом, чтобы, как только мы получим необходимую информацию при обходе дерева, мы просто использовали ее.
private static void visitChildNodes(NodeList nList) {for(int temp = 0; temp < nList.getLength(); temp++) {Node node = nList.item(temp);if(node.getNodeType() == Node.ELEMENT_NODE) {System.out.println("Node Name = " + node.getNodeName() + "; Value = " + node.getTextContent());//Check all attributesif(node.hasAttributes()) {// get attributes names and valuesNamedNodeMap nodeMap = node.getAttributes();for(int i = 0; i < nodeMap.getLength(); i++) {Node tempNode = nodeMap.item(i);System.out.println("Attr name : " + tempNode.getNodeName() + "; Value = " + tempNode.getNodeValue());}if(node.hasChildNodes()) {//We got more children; Let's visit them as wellvisitChildNodes(node.getChildNodes());}}}}}Вывод программы.
employees============================Node Name = employee; Value =LokeshGuptaIndiaAttr name : id; Value = 111Node Name = firstName; Value = LokeshNode Name = lastName; Value = GuptaNode Name = location; Value = IndiaNode Name = employee; Value =AlexGussinRussiaAttr name : id; Value = 222Node Name = firstName; Value = AlexNode Name = lastName; Value = GussinNode Name = location; Value = RussiaNode Name = employee; Value =DavidFeezorUSAAttr name : id; Value = 333Node Name = firstName; Value = DavidNode Name = lastName; Value = FeezorNode Name = location; Value = USA
Вот и все о полезной концепции Java XML DOM Parser. Напишите мне в комментариях, если что-то непонятно ИЛИ нужно больше объяснений.