Научитесь читать большой файл Excel на Java с помощью Apache POI и библиотеки парсера SAX. Парсер SAX — это парсер на основе событий. В отличие от парсера DOM, парсер SAX не создает дерево разбора и отправляет уведомления о событиях, когда лист, строка или ячейка обрабатываются последовательно сверху вниз.
В этом примере мы сможем:
- Используйте пользовательскую логику, чтобы выбрать, хотим ли мы обрабатывать определенный лист(по имени листа).
- Уведомлять о начале нового листа или окончании текущего листа.
- Получите первую строку на листе в качестве заголовков.
- Получить остальные строки на листе в виде карты пар имен столбцов и значений ячеек.
1. Зависимости Maven
Добавьте в приложение последнюю версию org.apache.poi:poi и org.apache.poi:poi-ooxml, если она еще не добавлена.
<dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.2</version></dependency>
2. Основные классы
- OPCPackage: Файл .xlsx создается поверх структуры пакета OOXML, а OPCPackage представляет собой контейнер, который может хранить несколько объектов данных.
- XSSFReader: упрощает доступ к отдельным частям файла OOXML .xlsx, подходит для анализа саксофонов с небольшим объемом памяти.
- DefaultHandler: предоставляет реализации по умолчанию для всех обратных вызовов в других основных классах обработчиков SAX2. Мы расширили этот класс и переопределили необходимые методы для обработки обратных вызовов событий.
- SAXParser: анализирует документ и отправляет уведомления о различных событиях парсера зарегистрированному обработчику событий.
- SharedStringsTable: хранит таблицу строк, общих для всех листов рабочей книги. Помогает повысить производительность, когда некоторые строки повторяются во многих строках или столбцах. Таблица общих строк содержит всю необходимую информацию для отображения строки: текст, свойства форматирования и фонетические свойства.
См. также: DOM против SAX Parser
3. Чтение Excel с помощью SAX Parser
3.1 Переопределение DefaultHandler
Давайте начнем с создания обработчика событий для разбора событий. Следующий SheetHandler расширяет DefaultHandler и предоставляет следующие методы:
- startElement(): вызывается, когда начинается новая строка или ячейка.
- endElement(): вызывается, когда заканчивается текущая строка или ячейка.
- readExcelFile(): берет файл Excel и использует SAXParser и XSSFReader для его постраничного анализа.
import org.apache.poi.openxml4j.opc.OPCPackage;import org.apache.poi.xssf.eventusermodel.XSSFReader;import org.apache.poi.xssf.model.SharedStringsTable;import org.apache.poi.xssf.usermodel.XSSFRichTextString;import org.xml.sax.Attributes;import org.xml.sax.SAXException;import org.xml.sax.helpers.DefaultHandler;import javax.xml.parsers.SAXParser;import javax.xml.parsers.SAXParserFactory;import java.io.File;import java.io.InputStream;import java.util.HashMap;import java.util.Iterator;import java.util.Map;import java.util.concurrent.ExecutionException;public class SheetHandler extends DefaultHandler{protected Map<String, String> header = new HashMap<>();protected Map<String, String> rowValues = new HashMap<>();private SharedStringsTable sharedStringsTable;protected long rowNumber = 0;protected String cellId;private String contents;private boolean isCellValue;private boolean fromSST;protected static String getColumnId(String attribute) throws SAXException {for(int i = 0; i < attribute.length(); i++) {if(!Character.isAlphabetic(attribute.charAt(i))) {return attribute.substring(0, i);}}throw new SAXException("Invalid format " + attribute);}@Overridepublic void startElement(String uri, String localName, String name,Attributes attributes) throws SAXException {// Clear contents cachecontents = "";// element row represents Rowswitch(name) {case "row" -> {String rowNumStr = attributes.getValue("r");rowNumber = Long.parseLong(rowNumStr);}// element c represents Cellcase "c" -> {cellId = getColumnId(attributes.getValue("r"));// attribute t represents the cell typeString cellType = attributes.getValue("t");if(cellType != null && cellType.equals("s")) {// cell type s means value will be extracted from SharedStringsTablefromSST = true;}}// element v represents value of Cellcase "v" -> isCellValue = true;}}@Overridepublic void characters(char[] ch, int start, int length) {if(isCellValue) {contents += new String(ch, start, length);}}@Overridepublic void endElement(String uri, String localName, String name) {if(isCellValue && fromSST) {int index = Integer.parseInt(contents);contents = new XSSFRichTextString(sharedStringsTable.getItemAt(index).getString()).toString();rowValues.put(cellId, contents);cellId = null;isCellValue = false;fromSST = false;} else if(isCellValue) {rowValues.put(cellId, contents);isCellValue = false;} else if(name.equals("row")) {header.clear();if(rowNumber == 1) {header.putAll(rowValues);}try {processRow();} catch(ExecutionException | InterruptedException e) {e.printStackTrace();}rowValues.clear();}}protected boolean processSheet(String sheetName) {return true;}protected void startSheet() {}protected void endSheet() {}protected void processRow() throws ExecutionException, InterruptedException {}public void readExcelFile(File file) throws Exception {SAXParserFactory factory = SAXParserFactory.newInstance();SAXParser saxParser = factory.newSAXParser();try(OPCPackage opcPackage = OPCPackage.open(file)) {XSSFReader xssfReader = new XSSFReader(opcPackage);sharedStringsTable =(SharedStringsTable) xssfReader.getSharedStringsTable();System.out.println(sharedStringsTable.getUniqueCount());Iterator<InputStream> sheets = xssfReader.getSheetsData();if(sheets instanceof XSSFReader.SheetIterator sheetIterator) {while(sheetIterator.hasNext()) {try(InputStream sheet = sheetIterator.next()) {String sheetName = sheetIterator.getSheetName();if(!processSheet(sheetName)) {continue;}startSheet();saxParser.parse(sheet, this);endSheet();}}}}}}3.2 Создание обработчика строк
Следующий класс ExcelReaderHandler расширяет класс SheetHandler, как указано в предыдущем разделе. Он переопределяет следующие методы, чтобы мы могли написать нашу собственную логику для обработки данных, считываемых с каждого листа в файле Excel.
- processSheet(): для определения, хотим ли мы прочитать лист или нет. Он принимает имя листа как параметр, который мы можем использовать для определения решения.
- startSheet(): вызывается каждый раз при запуске нового листа.
- endSheet(): вызывается каждый раз, когда заканчивается текущий лист.
- processRow(): вызывается один раз для каждой строки и предоставляет значения ячеек в этой строке.
public class ExcelReaderHandler extends SheetHandler {@Overrideprotected boolean processSheet(String sheetName) {//Decide which sheets to read; Return true for all sheets//return "Sheet 1".equals(sheetName);System.out.println("Processing start for sheet : " + sheetName);return true;}@Overrideprotected void startSheet() {//Any custom logic when a new sheet startsSystem.out.println("Sheet starts");}@Overrideprotected void endSheet() {//Any custom logic when sheet endsSystem.out.println("Sheet ends");}@Overrideprotected void processRow() {if(rowNumber == 1 && !header.isEmpty()) {System.out.println("The header values are at line no. " + rowNumber + " " +"are :" + header);}else if(rowNumber > 1 && !rowValues.isEmpty()) {//Get specific values here/*String a = rowValues.get("A");String b = rowValues.get("B");*///Print whole rowSystem.out.println("The row values are at line no. " + rowNumber + " are :" + rowValues);}}}4. Демонстрация
Давайте разберемся, как читать файл Excel с помощью демонстрационной программы. Мы читаем файл, который имеет 2 листа и некоторые значения на листах.
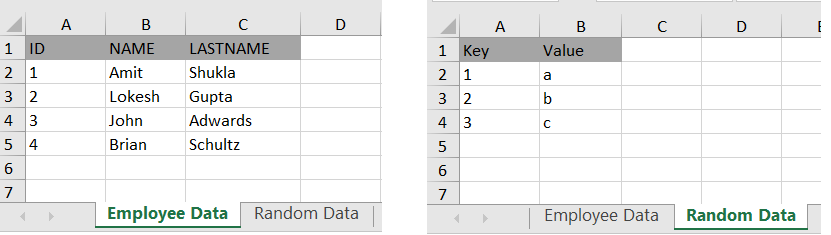
Давайте воспользуемся ExcelReaderHandler для чтения Excel и вывода считанных в процессе значений.
import java.io.File;import java.net.URL;public class ReadExcelUsingSaxParserExample {public static void main(String[] args) throws Exception {URL url = ReadExcelUsingSaxParserExample.class.getClassLoader().getResource("howtodoinjava_demo.xlsx");new ExcelReaderHandler().readExcelFile(new File(url.getFile()));}}Проверьте вывод, содержащий значения ячеек из файла Excel.
Processing start for sheet : Employee DataSheet startsThe header values are at line no. 1 are :{A=ID, B=NAME, C=LASTNAME}The row values are at line no. 2 are :{A=1, B=Amit, C=Shukla}The row values are at line no. 3 are :{A=2, B=Lokesh, C=Gupta}The row values are at line no. 4 are :{A=3, B=John, C=Adwards}The row values are at line no. 5 are :{A=4, B=Brian, C=Schultz}Sheet endsProcessing start for sheet : Random DataSheet startsThe header values are at line no. 1 are :{A=Key, B=Value}The row values are at line no. 2 are :{A=1, B=a}The row values are at line no. 3 are :{A=2, B=b}The row values are at line no. 4 are :{A=3, B=c}Sheet ends5. Заключение
В этом уроке Apache POI мы научились читать файл Excel с помощью парсера SAX. Мы можем использовать это решение и для чтения огромных файлов Excel. Я предложу вам поиграть с кодом для лучшего понимания.