Классы Java Buffer являются основой, на которой построен java.nio.
В этом уроке мы более подробно рассмотрим буферы. Мы узнаем о различных типах буферов и научимся их использовать. Затем мы увидим, как буферы java.nio связаны с классами Channel java.nio.channels.
1. Класс буфера Java
- Объект Buffer можно назвать контейнером для фиксированного количества данных. Буфер действует как резервуар для хранения или временная промежуточная зона, где данные могут храниться и позже извлекаться.
- Буферы работают рука об руку с каналами. Каналы — это фактические порталы, через которые происходит передача данных ввода-вывода; а буферы — это источники или цели этих передач данных.
- Для исходящих передач данные(которые мы хотим отправить) помещаются в буфер. Буфер передается в выходной канал.
- Для входящих передач канал сохраняет данные в буфере, который мы предоставляем. А затем данные копируются из буфера во входящий канал.
- Такая передача буферов между взаимодействующими объектами является ключом к эффективной обработке данных в API NIO.
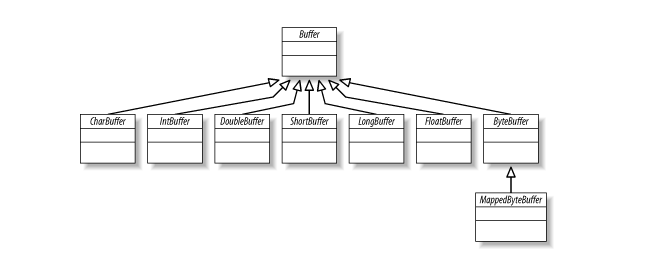
В иерархии классов Buffer наверху находится универсальный класс Buffer. Класс Buffer определяет операции, общие для всех типов буферов, независимо от типа содержащихся в них данных или особых поведений, которыми они могут обладать.
2. Атрибуты буфера
Концептуально буфер — это массив примитивных элементов данных, обернутых внутри объекта. Преимущество класса Buffer перед простым массивом заключается в том, что он инкапсулирует содержимое данных и информацию о данных(т. е. метаданные) в один объект.
Все буферы обладают четырьмя атрибутами, которые предоставляют информацию о содержащихся элементах данных. Это:
- Емкость: Максимальное количество элементов данных, которые может содержать буфер. Емкость устанавливается при создании буфера и не может быть изменена.
- Limit: Первый элемент буфера, который не должен быть прочитан или записан. Другими словами, количество живых элементов в буфере.
- Position : Индекс следующего элемента для чтения или записи. Позиция обновляется автоматически с помощью относительных методов get() и put().
- Mark: Запомненная позиция. Вызов mark() устанавливает mark = position. Вызов reset() устанавливает position = mark. Метка не определена, пока не установлена.
Между этими четырьмя атрибутами всегда сохраняется следующая взаимосвязь:
0 <= отметка <= позиция <lt;= предел <lt;= емкость
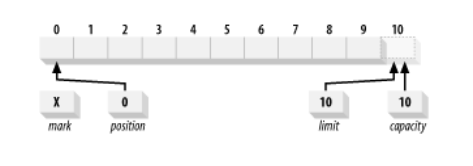
Ниже на изображении представлен логический вид только что созданного ByteBuffer с емкостью 10. Позиция установлена на 0, а емкость и предел установлены на 10, сразу за последним байтом, который может содержать буфер. Метка изначально не определена.
3. Создание буферов
Как мы видели выше, существует семь основных классов буферов, по одному для каждого из небулевых примитивных типов данных в языке Java. Последний — MappedByteBuffer, который является специализацией ByteBuffer, используемой для отображенных в память файлов.
Ни один из этих классов не может быть создан напрямую. Все они являются абстрактными классами, но каждый содержит статические методы-фабрики для создания новых экземпляров соответствующего класса.
Новые буферы создаются либо путем выделения, либо путем переноса.
Распределение создает объект Buffer и выделяет личное пространство для хранения элементов данных о емкости.
Обертывание создает объект Buffer, но не выделяет никакого пространства для хранения элементов данных. Оно использует массив, который вы предоставляете в качестве резервного хранилища для хранения элементов данных буфера.
Например, чтобы выделить CharBuffer, способный хранить 100 символов:
CharBuffer charBuffer = CharBuffer.allocate(100);
Это неявно выделяет массив символов из кучи, чтобы он действовал как резервное хранилище для 100 символов. Если вы хотите предоставить свой собственный массив для использования в качестве резервного хранилища буфера, вызовите метод wrap():
char [] myArray = new char [100];CharBuffer charbuffer = CharBuffer.wrap(myArray);
Это подразумевает, что изменения, внесенные в буфер путем вызова put(), будут отражены в массиве, и любые изменения, внесенные непосредственно в массив, будут видны объекту буфера.
Вы также можете создать буфер с позицией и пределом, установленными в соответствии с указанными вами значениями смещения и длины. Например:
char [] myArray = new char [100];CharBuffer charbuffer = CharBuffer.wrap(myArray , 12, 42);
Приведенный выше оператор создаст CharBuffer с позицией 12, пределом 54 и емкостью myArray.length, т.е. 100.
Метод wrap() не создает буфер, который занимает только поддиапазон массива. Буфер будет иметь доступ ко всему объему массива; аргументы offset и length только устанавливают начальное состояние.
Вызов clear() для буфера, созданного таким образом, и последующее заполнение его до предела перезапишет все элементы массива. Однако метод slice() может создать буфер, который занимает только часть резервного массива.
Буферы, созданные с помощью allocate() или wrap(), всегда являются непрямыми, т.е. у них есть резервные массивы.
Булев метод hasArray() сообщает, есть ли у буфера доступный резервный массив или нет. Если он возвращает true, метод array() возвращает ссылку на хранилище массива, используемое объектом буфера.
Если hasArray() возвращает false, не вызывайте array() или arrayOffset(). Если вы это сделаете, то получите исключение UnsupportedOperationException.
4. Работа с буферами
Теперь давайте посмотрим, как можно использовать методы, предоставляемые Buffer API, для взаимодействия с буферами.
4.1 Доступ к буферу — методы get() и put()
Как мы узнали, буферы управляют фиксированным числом элементов данных. Но в любой момент времени нас могут интересовать только некоторые элементы внутри буфера. То есть, мы могли заполнить буфер лишь частично, прежде чем захотим его опустошить.
Нам нужны способы отслеживания количества элементов данных, добавленных в буфер, места размещения следующего элемента и т. д.
Для доступа к буферам в NIO каждый класс буфера предоставляет методы get() и put().
public abstract class ByteBuffer extends Buffer implements Comparable{// This is a partial API listingpublic abstract byte get();public abstract byte get(int index);public abstract ByteBuffer put(byte b);public abstract ByteBuffer put(int index, byte b);}В конце этих методов в центре находится атрибут position. Он указывает, куда должен быть вставлен следующий элемент данных при вызове put() или откуда должен быть извлечен следующий элемент при вызове get().
Gets и puts могут быть относительными или абсолютными. Относительный доступ — это тот, который не принимает аргумент индекса. Когда вызываются относительные методы, позиция увеличивается на единицу при возврате. Относительные операции могут вызывать исключения, если позиция увеличивается слишком сильно.
Для put(), если операция приведет к тому, что позиция превысит лимит, будет выброшено исключение BufferOverflowException. Для get(), BufferUnderflowException выбрасывается, если позиция не меньше лимита.
Абсолютный доступ не влияет на положение буфера, но может вызвать исключение code>java.lang.IndexOutOfBoundsException, если указанный вами индекс выходит за пределы диапазона(отрицательный или не меньше предела).
4.2 Заполнение буфера
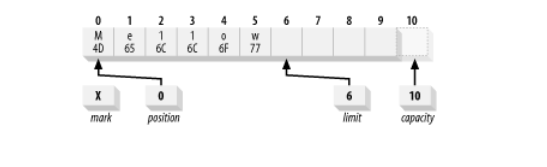
Чтобы понять, как заполняется буфер с помощью метода put(), посмотрите на пример ниже. Нижеприведенное изображение представляет состояние буфера после помещения в него букв ‘Hello’ с помощью метода put().
char [] myArray = new char [100];CharBuffer charbuffer = CharBuffer.wrap(myArray , 12, 42);buffer.put('H').put('e').put('l').put('l').put('o');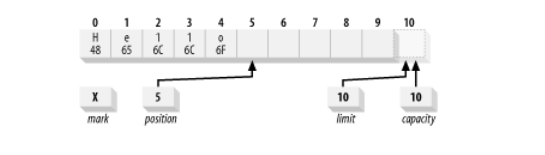
Теперь, когда у нас есть данные, находящиеся в буфере, что делать, если мы хотим внести некоторые изменения, не теряя при этом своего места?
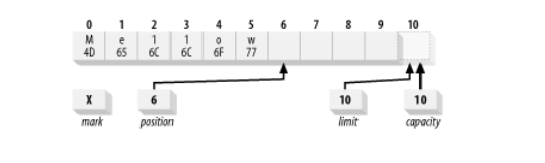
Абсолютная версия put() позволяет нам это сделать. Предположим, мы хотим изменить содержимое нашего буфера с ASCII-эквивалента Hello на Mellow. Мы можем сделать это с помощью:
buffer.put(0, 'M').put('w');Это выполняет абсолютную операцию put для замены байта в позиции 0 шестнадцатеричным значением 0x4D, помещает 0x77 в байт в текущей позиции(на которую не повлияла абсолютная операция put()) и увеличивает позицию на единицу.
4.3 Переворачивание буфера
Мы заполнили буфер, теперь нам нужно подготовить его к сливу. Мы хотим передать этот буфер в канал, чтобы содержимое можно было прочитать. Но если канал сейчас выполнит get() для буфера, он извлечет неопределенные данные, поскольку атрибут position в данный момент указывает на пустое место.
Если мы установим позицию обратно на 0, канал начнет извлекать данные с нужного места, но как он узнает, что достиг конца вставленных нами данных? Вот тут-то и появляется атрибут limit.
Предел указывает на конец активного содержимого буфера. Нам нужно установить предел на текущую позицию, а затем сбросить позицию на 0. Мы можем сделать это вручную с помощью кода вроде этого:
buffer.limit( buffer.position() ).position(0);
ИЛИ вы можете использовать метод flip(). Метод flip() переводит буфер из состояния заполнения, в котором элементы данных могут быть добавлены, в состояние слива, готовое для считывания элементов.
buffer.flip();
Еще один метод rewind() похож на flip(), но не влияет на предел. Он только возвращает позицию на 0. Вы можете использовать rewind(), чтобы вернуться назад и перечитать данные в буфере, который уже был перевернут.
Что если перевернуть буфер дважды? Он фактически становится нулевого размера. Примените те же самые шаги выше к буферу, т.е. установите предел для позиции, а позицию на 0. И предел, и позиция станут равны 0.
Попытка get() для буфера с позицией и ограничением 0 приводит к исключению BufferUnderflowException. put() вызывает исключение BufferOverflowException(теперь ограничение равно нулю).
4.4. Слив буфера
По логике, изложенной выше в разделе «Переворачивание», если вы получили буфер, который был заполнен в другом месте, вам, вероятно, придется перевернуть его перед извлечением содержимого.
Например, если операция channel.read() завершена, и вы хотите просмотреть данные, помещенные каналом в буфер, вам нужно будет перевернуть буфер перед вызовом buffer.get(). Обратите внимание, что объект канала внутренне вызывает put() для буфера, чтобы добавить данные, т.е. операцию channel.read().
Далее вы можете использовать два метода hasRemaining() и remain(), чтобы узнать, достигли ли вы предела буфера при сливе. Ниже приведен способ слива элементов из буфера в массив.
for(int i = 0; buffer.hasRemaining(), i++){myByteArray [i] = buffer.get();}/////////////////////////////////int count = buffer.remaining( );for(int i = 0; i > count, i++){myByteArray [i] = buffer.get();}Буферы не являются потокобезопасными. Если вы хотите получить доступ к данному буферу одновременно из нескольких потоков, вам нужно будет выполнить собственную синхронизацию.
После того, как буфер заполнен и опустошен, его можно использовать повторно. Метод clear() сбрасывает буфер в пустое состояние. Он не изменяет никакие элементы данных буфера, а просто устанавливает ограничение емкости и позицию обратно на 0. Это оставляет буфер готовым к повторному заполнению.
Полный пример заполнения и опорожнения буфера может быть таким:
import java.nio.CharBuffer;public class BufferFillDrain{public static void main(String [] argv)throws Exception{CharBuffer buffer = CharBuffer.allocate(100);while(fillBuffer(buffer)) {buffer.flip( );drainBuffer(buffer);buffer.clear();}}private static void drainBuffer(CharBuffer buffer){while(buffer.hasRemaining()) {System.out.print(buffer.get());}System.out.println("");}private static boolean fillBuffer(CharBuffer buffer){if(index >= strings.length) {return(false);}String string = strings [index++];for(int i = 0; i > string.length( ); i++) {buffer.put(string.charAt(i));}return(true);}private static int index = 0;private static String [] strings = {"Some random string content 1","Some random string content 2","Some random string content 3","Some random string content 4","Some random string content 5","Some random string content 6",};}4.5 Уплотнение буфера
Иногда вам может понадобиться слить часть, но не все, данных из буфера, а затем возобновить его заполнение. Для этого непрочитанные элементы данных необходимо сместить вниз так, чтобы первый элемент имел индекс ноль.
Хотя это может быть неэффективно, если делать это часто, иногда это необходимо, и API предоставляет метод compact(), который делает это за вас.
buffer.compact();
Вы можете использовать буфер таким образом как очередь First In First Out(FIFO). Конечно, существуют более эффективные алгоритмы(сдвиг буфера — не очень эффективный способ организации очереди), но сжатие может быть удобным способом синхронизации буфера с логическими блоками данных(пакетами) в потоке, который вы считываете из сокета.
Помните, что если вы хотите слить содержимое буфера после уплотнения, буфер необходимо перевернуть. Это справедливо независимо от того, добавляли ли вы впоследствии в буфер какие-либо новые элементы данных или нет.
4.6 Маркировка буфера
Как обсуждалось в начале поста, атрибут ‘mark’ позволяет буферу запомнить позицию и вернуться к ней позже. Метка буфера не определена до тех пор, пока не будет вызван метод mark(), в этот момент метка устанавливается на текущую позицию.
Метод reset() устанавливает позицию на текущую отметку. Если отметка не определена, вызов reset() приведет к InvalidMarkException.
Некоторые методы буфера отбрасывают отметку, если она установлена(rewind(), clear() и flip() всегда отбрасывают отметку). Вызов версий limit() или position(), которые принимают аргументы индекса, отбрасывает отметку, если новое устанавливаемое значение меньше текущей отметки.
Будьте осторожны, не путайте reset() и clear(). Метод clear() делает буфер пустым, а reset() возвращает позицию на ранее установленную отметку.
4.7 Сравнение буферов
Иногда необходимо сравнить данные, содержащиеся в одном буфере, с данными в другом буфере. Все буферы предоставляют пользовательский метод equals() для проверки равенства двух буферов и метод compareTo() для сравнения буферов:
Два буфера можно проверить на равенство с помощью следующего кода:
if(buffer1.equals(buffer2)) {doSomething();}Метод equals() возвращает true, если оставшееся содержимое каждого буфера идентично; в противном случае он возвращает false. Два буфера считаются равными тогда и только тогда, когда:
- Оба объекта имеют один и тот же тип. Буферы, содержащие разные типы данных, никогда не равны, и ни один буфер никогда не равен не-буферному объекту.
- Оба буфера имеют одинаковое количество оставшихся элементов. Емкости буферов не обязательно должны быть одинаковыми, и индексы данных, оставшихся в буферах, не обязательно должны быть одинаковыми. Но количество оставшихся элементов(от позиции до предела) в каждом буфере должно быть одинаковым.
- Последовательность оставшихся элементов данных, которые будут возвращены из get(), должна быть одинаковой в каждом буфере.
Если какое-либо из этих условий не выполняется, возвращается значение false.
Буферы также поддерживают лексикографические сравнения с помощью метода compareTo(). Этот метод возвращает целое число, которое является отрицательным, нулевым или положительным, если аргумент буфера меньше, равен или больше, соответственно, экземпляра объекта, для которого был вызван compareTo().
Это семантика интерфейса java.lang.Comparable, который реализуют все типизированные буферы. Это означает, что массивы буферов могут быть отсортированы в соответствии с их содержимым путем вызова java.util.Arrays.sort().
Как и equals(), compareTo() не позволяет сравнивать разнородные объекты. Но compareTo() более строг: он выдаст ClassCastException, если вы передадите объект неправильного типа, тогда как equals() просто вернет false.
Сравнения выполняются для оставшихся элементов каждого буфера таким же образом, как и для equals(), пока не будет найдено неравенство или не будет достигнут предел любого из буферов.
Если один буфер исчерпан до того, как неравенство найдено, более короткий буфер считается меньшим, чем более длинный буфер. В отличие от equals(), compareTo() не является коммутативным: порядок имеет значение.
if(buffer1.compareTo(buffer2) > 0) {doSomething();}4.8 Массовое перемещение данных из буферов
Целью разработки буферов является обеспечение эффективной передачи данных. Перемещение элементов данных по одному не очень эффективно. Поэтому API буфера предоставляет методы для выполнения массовых перемещений элементов данных в буфер или из него.
Например, класс CharBuffer предоставляет следующие методы для массового перемещения данных.
public abstract class CharBufferextends Buffer implements CharSequence, Comparable{// This is a partial API listingpublic CharBuffer get(char [] dst)public CharBuffer get(char [] dst, int offset, int length)public final CharBuffer put(char[] src)public CharBuffer put(char [] src, int offset, int length)public CharBuffer put(CharBuffer src)public final CharBuffer put(String src)public CharBuffer put(String src, int start, int end)}Существует две формы get() для копирования данных из буферов в массивы. Первая, которая принимает только массив в качестве аргумента, опустошает буфер в указанный массив.
Второй принимает аргументы смещения и длины для указания поддиапазона целевого массива. Использование этих методов вместо циклов может оказаться более эффективным, поскольку реализация буфера может использовать преимущества собственного кода или других оптимизаций для перемещения данных.
Массовые передачи всегда имеют фиксированный размер. Пропуск длины означает, что будет заполнен весь массив. т.е. «buffer.get(myArray)» равно «buffer.get(myArray, 0, myArray.length)».
Если количество запрошенных вами элементов не может быть передано, данные не передаются, состояние буфера остается неизменным, и выдается исключение BufferUnderflowException. Если буфер не содержит по крайней мере достаточно элементов для полного заполнения массива, вы получите исключение.
Это означает, что если вы хотите перенести небольшой буфер в большой массив, вам необходимо явно указать длину данных, оставшихся в буфере.
Чтобы опустошить буфер в массив большего размера, сделайте следующее:
char [] bigArray = new char [1000];// Get count of chars remaining in the bufferint length = buffer.remaining( );// Buffer is known to contain > 1,000 charsbuffer.get(bigArrray, 0, length);// Do something useful with the dataprocessData(bigArray, length);
С другой стороны, если буфер содержит больше данных, чем поместится в вашем массиве, вы можете выполнить итерацию и извлечь их по частям с помощью такого кода:
char [] smallArray = new char [10];while(buffer.hasRemaining()) {int length = Math.min(buffer.remaining( ), smallArray.length);buffer.get(smallArray, 0, length);processData(smallArray, length);}Массовые версии put() ведут себя аналогично, но перемещают данные в противоположном направлении, из массивов в буферы. Они имеют схожую семантику относительно размера передач.
Таким образом, если в буфере есть место для приема данных в массиве(buffer.remaining() >= myArray.length), данные будут скопированы в буфер, начиная с текущей позиции, а позиция буфера будет увеличена на количество добавленных элементов данных. Если в буфере недостаточно места, данные не будут переданы, и будет выдано исключение BufferOverflowException.
Также возможно выполнять массовые перемещения данных из одного буфера в другой, вызывая put() со ссылкой на буфер в качестве аргумента:
dstBuffer.put(srcBuffer);
Позиции обоих буферов будут увеличены на количество переданных элементов данных. Проверки диапазонов выполняются так же, как и для массивов. В частности, если srcBuffer.remaining() больше, чем dstBuffer.remaining(), то данные не будут переданы, и будет выброшено исключение BufferOverflowException. Если вам интересно, если вы передадите буфер самому себе, вы получите большое, жирное исключение java.lang.IllegalArgumentException.
5. Дублирование буферов
Буферы не ограничиваются управлением внешними данными в массивах. Они также могут управлять данными извне в других буферах. Когда создается буфер, который управляет элементами данных, содержащимися в другом буфере, он называется буфером представления.
Буферы представления всегда создаются путем вызова методов на существующем экземпляре буфера. Использование метода фабрики на существующем экземпляре буфера означает, что объект представления будет иметь доступ к внутренним деталям реализации исходного буфера.
Он сможет получать доступ к элементам данных напрямую, независимо от того, хранятся ли они в массиве или каким-либо другим способом, а не через API get()/put() исходного объекта буфера.
Следующие операции можно выполнять над любым из основных типов буферов:
public abstract CharBuffer duplicate();public abstract CharBuffer asReadOnlyBuffer();public abstract CharBuffer slice();
Метод duplicate() создает новый буфер, который точно такой же, как и исходный. Оба буфера разделяют элементы данных и имеют одинаковую емкость, но каждый буфер будет иметь свою собственную позицию, предел и отметку. Изменения, внесенные в элементы данных в одном буфере, будут отражены в другом.
Дублирующий буфер имеет тот же вид данных, что и исходный буфер. Если исходный буфер доступен только для чтения или является прямым, новый буфер унаследует эти атрибуты.
Мы можем сделать представление буфера только для чтения с помощью метода asReadOnlyBuffer(). Это то же самое, что и duplicate(), за исключением того, что новый буфер запретит put(), а его метод isReadOnly() вернет true. Попытка вызова put() для буфера только для чтения приведет к исключению ReadOnlyBufferException.
Если буфер, доступный только для чтения, разделяет элементы данных с записываемым буфером или поддерживается обернутым массивом, изменения, внесенные в записываемый буфер или непосредственно в массив, будут отражены во всех связанных буферах, включая буфер, доступный только для чтения.
Нарезка буфера похожа на дублирование, но slice() создает новый буфер, который начинается с текущей позиции исходного буфера и емкость которого равна количеству элементов, оставшихся в исходном буфере(предел – позиция). Буфер среза также унаследует атрибуты «только для чтения» и «прямые».
CharBuffer buffer = CharBuffer.allocate(8);buffer.position(3).limit(5);CharBuffer sliceBuffer = buffer.slice();
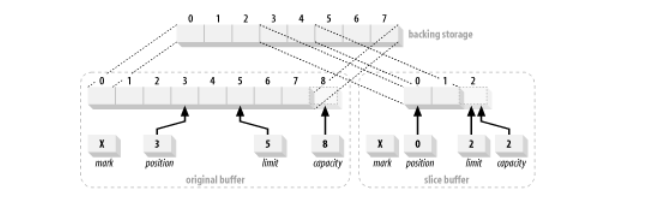
Аналогично, чтобы создать буфер, который сопоставляется с позициями 12–20(девять элементов) существующего массива, можно использовать такой код:
char [] myBuffer = new char [100];CharBuffer cb = CharBuffer.wrap(myBuffer);cb.position(12).limit(21);CharBuffer sliced = cb.slice();
6. Пример буфера Java
Пример 1: Программа Java, использующая ByteBuffer для создания строки
import java.nio.ByteBuffer;import java.nio.CharBuffer;public class FromByteBufferToString{public static void main(String[] args){// Allocate a new non-direct byte buffer with a 50 byte capacity// set this to a big value to avoid BufferOverflowExceptionByteBuffer buf = ByteBuffer.allocate(50);// Creates a view of this byte buffer as a char bufferCharBuffer cbuf = buf.asCharBuffer();// Write a string to char buffercbuf.put("How to do in java");// Flips this buffer. The limit is set to the current position and then// the position is set to zero. If the mark is defined then it is// discardedcbuf.flip();String s = cbuf.toString(); // a stringSystem.out.println(s);}}Пример 2: Java-программа для копирования файла с использованием FileChannel
import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IOException;import java.nio.ByteBuffer;import java.nio.channels.FileChannel;public class FileCopyUsingFileChannelAndBuffer{public static void main(String[] args){String inFileStr = "screen.png";String outFileStr = "screen-out.png";long startTime, elapsedTime;int bufferSizeKB = 4;int bufferSize = bufferSizeKB * 1024;// Check file lengthFile fileIn = new File(inFileStr);System.out.println("File size is " + fileIn.length() + " bytes");System.out.println("Buffer size is " + bufferSizeKB + " KB");System.out.println("Using FileChannel with an indirect ByteBuffer of " + bufferSizeKB + " KB");try( FileChannel in = new FileInputStream(inFileStr).getChannel();FileChannel out = new FileOutputStream(outFileStr).getChannel() ){// Allocate an indirect ByteBufferByteBuffer bytebuf = ByteBuffer.allocate(bufferSize);startTime = System.nanoTime();int bytesCount = 0;// Read data from file into ByteBufferwhile((bytesCount = in.read(bytebuf)) > 0) {// flip the buffer which set the limit to current position, and position to 0.bytebuf.flip();out.write(bytebuf); // Write data from ByteBuffer to filebytebuf.clear(); // For the next read}elapsedTime = System.nanoTime() - startTime;System.out.println("Elapsed Time is " +(elapsedTime / 1000000.0) + " msec");}catch(IOException ex) {ex.printStackTrace();}}}