Эта статья предназначена для читателей, которым интересно узнать, как операции ввода-вывода Java отображаются на уровне машины, а также какие действия выполняет оборудование во время работы вашего приложения.
Я предполагаю, что вы знакомы с основными операциями ввода-вывода, такими как чтение файла и запись файла через API ввода-вывода Java, поскольку это выходит за рамки данной статьи.
1. Обработка буфера и ядро против пространства пользователя
Сам термин «ввод/вывод» означает не что иное, как перемещение данных в буферы и из них.
Буферы и то, как буферы обрабатываются, являются основой всего IO. Просто помните об этом все время.
Обычно процессы выполняют IO, запрашивая у операционной системы, чтобы данные были слиты из буфера(операция записи) или чтобы буфер был заполнен данными(операция чтения). Это все резюме концепций IO.
Механизм внутри операционной системы, который выполняет эти передачи, может быть невероятно сложным, но концептуально он очень прост, и в этой статье мы обсудим лишь небольшую его часть.
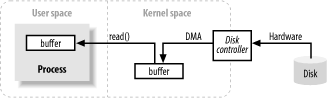
На изображении выше показана упрощенная «логическая» схема перемещения блока данных из внешнего источника, например жесткого диска, в область памяти внутри запущенного процесса(например, ОЗУ).
- Прежде всего, процесс запрашивает заполнение своего буфера, выполняя системный вызов read().
- Вызов чтения приводит к тому, что ядро выдает команду оборудованию контроллера диска на извлечение данных с диска.
- Контроллер диска записывает данные непосредственно в буфер памяти ядра с помощью DMA без дальнейшей помощи со стороны основного процессора.
- После того как контроллер диска завершает заполнение буфера, ядро копирует данные из временного буфера в пространстве ядра в буфер, указанный процессом; при запросе операции read().
Следует отметить, что ядро пытается кэшировать и/или предварительно извлекать данные, поэтому запрашиваемые процессом данные могут уже быть доступны в пространстве ядра. Если это так, запрашиваемые процессом данные копируются.
Если данные недоступны, процесс приостанавливается, пока ядро загружает данные в память.
2. Виртуальная память
Вы, должно быть, уже много раз слышали о виртуальной памяти. Позвольте мне высказать некоторые мысли по этому поводу.
Все современные операционные системы используют виртуальную память. Виртуальная память означает, что вместо адресов физической(аппаратной RAM) памяти используются искусственные или виртуальные адреса.
Виртуальная память имеет два важных преимущества:
- К одному и тому же участку физической памяти может относиться несколько виртуальных адресов.
- Объем виртуальной памяти может превышать фактически доступный объем аппаратной памяти.
В предыдущем разделе копирование из пространства ядра в конечный буфер пользователя должно было показаться дополнительной работой. Почему бы не сказать контроллеру диска отправить его напрямую в буфер в пространстве пользователя? Ну, это делается с использованием виртуальной памяти и ее преимущество номер 1 выше.
Сопоставляя адрес пространства ядра с тем же физическим адресом, что и виртуальный адрес в пространстве пользователя, оборудование DMA(которое может обращаться только к физическим адресам памяти) может заполнить буфер, который одновременно виден как ядру, так и процессу в пространстве пользователя.
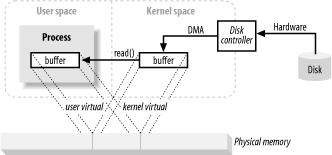
Это устраняет копии между ядром и пользовательским пространством, но требует, чтобы ядро и пользовательские буферы разделяли одно и то же выравнивание страниц. Буферы также должны быть кратны размеру блока, используемого контроллером диска(обычно 512-байтовые секторы диска).
Операционные системы делят адресные пространства памяти на страницы, которые представляют собой группы байтов фиксированного размера. Эти страницы памяти всегда кратны размеру блока диска и обычно являются степенями 2(что упрощает адресацию). Типичные размеры страниц памяти составляют 1024, 2048 и 4096 байт.
Размеры страниц виртуальной и физической памяти всегда одинаковы.
3. Страничная разбивка памяти
Для поддержки второго преимущества виртуальной памяти(наличие адресуемого пространства большего, чем физическая память) необходимо выполнять страничное разбиение виртуальной памяти(часто называемое подкачкой).
Память Paging — это схема, при которой страницы пространства виртуальной памяти могут быть сохранены на внешнем дисковом хранилище, чтобы освободить место в физической памяти для других виртуальных страниц. По сути, физическая память действует как кэш для области подкачки, которая является пространством на диске, где хранится содержимое страниц памяти, когда они вытесняются из физической памяти.
Выравнивание размеров страниц памяти как кратных размеру блока диска позволяет ядру выдавать прямые команды оборудованию контроллера диска для записи страниц памяти на диск или их перезагрузки при необходимости.
Оказывается, что все дисковые операции ввода-вывода выполняются на уровне страниц. Это единственный способ перемещения данных между диском и физической памятью в современных операционных системах с подкачкой страниц.
Современные ЦП содержат подсистему, известную как Блок управления памятью(MMU). Это устройство логически располагается между ЦП и физической памятью. MMU содержит информацию о сопоставлении, необходимую для преобразования виртуальных адресов в адреса физической памяти.
Когда ЦП обращается к ячейке памяти, MMU определяет, на какой странице находится эта ячейка(обычно путем сдвига или маскирования битов значения адреса) и преобразует этот виртуальный номер страницы в физический номер страницы(это делается аппаратно и очень быстро).
4. Файл/Блочный ориентированный ввод-вывод
Файловый ввод-вывод всегда происходит в контексте файловой системы. Файловая система — это совсем не то же самое, что диск. Диски хранят данные в секторах, которые обычно имеют размер 512 байт каждый. Это аппаратные устройства, которые ничего не знают о семантике файлов. Они просто предоставляют несколько слотов, в которых могут храниться данные. В этом отношении сектора диска похожи на страницы памяти: все они имеют одинаковый размер и адресуются как большой массив.
С другой стороны, файловая система — это более высокий уровень абстракции. Файловые системы — это особый метод организации и интерпретации данных, хранящихся на диске(или другом устройстве с произвольным доступом, ориентированном на блоки). Код, который вы пишете, почти всегда взаимодействует с файловой системой, а не с дисками напрямую. Именно файловая система определяет абстракции имен файлов, путей, файлов, атрибутов файлов и т. д.
Файловая система организует(на жестком диске) последовательность блоков данных одинакового размера. Некоторые блоки хранят метаинформацию, такую как карты свободных блоков, каталоги, индексы и т. д. Другие блоки содержат фактические данные файлов.
Метаинформация об отдельных файлах описывает, какие блоки содержат данные файла, где заканчиваются данные, когда они последний раз обновлялись и т. д.
Когда пользовательский процесс делает запрос на чтение данных файла, реализация файловой системы определяет, где именно на диске находятся эти данные. Затем она предпринимает действия по переносу этих секторов диска в память.
Файловые системы также имеют понятие страниц, которые могут быть того же размера, что и базовая страница памяти или кратны ей. Типичные размеры страниц файловой системы варьируются от 2048 до 8192 байт и всегда будут кратны размеру базовой страницы памяти.
То, как страничная файловая система выполняет ввод-вывод, сводится к следующим логическим шагам:
- Определите, какие страницы файловой системы(группы секторов диска) охватывает запрос. Содержимое файла и/или метаданные на диске могут быть распределены по нескольким страницам файловой системы, и эти страницы могут быть несмежными.
- Выделите достаточно страниц памяти в пространстве ядра для хранения идентифицированных страниц файловой системы.
- Установите соответствия между этими страницами памяти и страницами файловой системы на диске.
- Сгенерировать ошибки страниц для каждой из этих страниц памяти.
- Система виртуальной памяти перехватывает ошибки страниц и планирует подкачку страниц(т. е. подкачку страниц пространства подкачки) для проверки этих страниц путем считывания их содержимого с диска.
- После завершения подкачки файловая система разбивает необработанные данные на части, чтобы извлечь запрошенное содержимое файла или информацию об атрибутах.
Обратите внимание, что эти данные файловой системы будут кэшироваться, как и другие страницы памяти. При последующих запросах ввода-вывода некоторые или все данные файла могут по-прежнему присутствовать в физической памяти и могут быть повторно использованы без повторного считывания с диска.
5. Блокировка файлов
Блокировка файлов — это схема, с помощью которой один процесс может запретить другим доступ к файлу или ограничить доступ других процессов к этому файлу. Хотя название «блокировка файлов» подразумевает блокировку всего файла(и это часто делается), блокировка обычно доступна на более мелкозернистом уровне.
Области файла обычно блокируются с гранулярностью до уровня байта. Блокировки связаны с определенным файлом, начиная с определенного местоположения байта в этом файле и продолжаясь в течение определенного диапазона байтов. Это важно, поскольку позволяет многим процессам координировать доступ к определенным областям файла, не мешая другим процессам, работающим в других местах файла.
Блокировки файлов бывают двух видов: общие и исключительные. Несколько общих блокировок могут действовать для одной и той же области файла одновременно. Исключительные блокировки, с другой стороны, требуют, чтобы никакие другие блокировки не действовали для запрашиваемой области.
6. Потоки ввода-вывода
Не все операции ввода-вывода ориентированы на блоки. Существует также потоковый ввод-вывод, который смоделирован на основе конвейера. Байты потока ввода-вывода должны быть доступны последовательно. Устройства TTY(консольные), порты принтеров и сетевые соединения являются типичными примерами потоков.
Потоки обычно, но не обязательно, медленнее блочных устройств и часто являются источником прерывистого ввода. Большинство операционных систем позволяют переводить потоки в неблокируемый режим, что позволяет процессу проверять, доступен ли ввод в потоке, не застревая, если в данный момент ничего не доступно. Такая возможность позволяет процессу обрабатывать ввод по мере его поступления, но выполнять другие функции, пока поток ввода простаивает.
Шаг за пределы неблокируемого режима — это возможность выбора готовности. Это похоже на неблокируемый режим(и часто строится поверх неблокируемого режима), но снимает проверку готовности потока для операционной системы.
Операционной системе можно приказать следить за коллекцией потоков и возвращать процессу указание на то, какие из этих потоков готовы. Эта способность позволяет процессу мультиплексировать множество активных потоков, используя общий код и один поток, используя информацию о готовности, возвращаемую операционной системой.
Stream IO широко используется в сетевых серверах для обработки большого количества сетевых подключений. Выбор готовности имеет важное значение для масштабирования больших объемов.
Вот и все по этой довольно сложной теме, содержащей массу технических терминов 🙂