Java HashMap является членом фреймворка Collections и хранит пары ключ-значение. Каждый ключ сопоставляется с одним значением, и дублирование ключей не допускается. В этом руководстве мы узнаем, как HashMap хранит пары ключ-значение внутри и как он предотвращает дублирование ключей.
1. Краткий обзор HashMap
HashMap хранит пары ключ-значение. Он связывает предоставленный ключ со значением, так что позже мы можем получить значение, используя ключ.
HashMap<String, String> map = new HashMap<>();map.put("key", "value"); //Storagemap.get("key"); // returns "value"Внутри пары ключ-значение хранятся как экземпляр экземпляров Map.entry, представленных Node. Каждый экземпляр класса Node содержит предоставленный ключ, значение, хэш объекта ключа и ссылку на следующий Node, если таковой имеется, как в LinkedList.
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;//...}Сгенерированный хэш объекта Key также сохраняется, чтобы избежать вычисления хэша каждый раз во время сравнений и повысить общую производительность.
2. Внутренняя реализация HashMap
HashMap — это реализация интерфейса Map на основе HashTable. Внутри себя он поддерживает массив, также называемый «массивом контейнеров». Размер массива контейнеров определяется начальной емкостью HashMap, по умолчанию — 16.
transient Node<K,V>[] table;
Каждая позиция индекса в массиве представляет собой контейнер, который может содержать несколько объектов Node с использованием LinkedList.

Как показано выше, возможно, что несколько ключей могут создать хэш, который сопоставляет их в один контейнер. Вот почему записи Map хранятся как LinkedList.
Но когда записи в одном контейнере достигают порогового значения(TREEIFY_THRESHOLD, значение по умолчанию 8), Map преобразует внутреннюю структуру контейнера из связанного списка в RedBlackTree( JEP 180 ). Все экземпляры Entry преобразуются в экземпляры TreeNode.
По сути, когда контейнер становится слишком большим, HashMap динамически заменяет его специальной реализацией TreeMap. Таким образом, вместо пессимистичной производительности O(n), мы получаем гораздо лучшую O(log n).
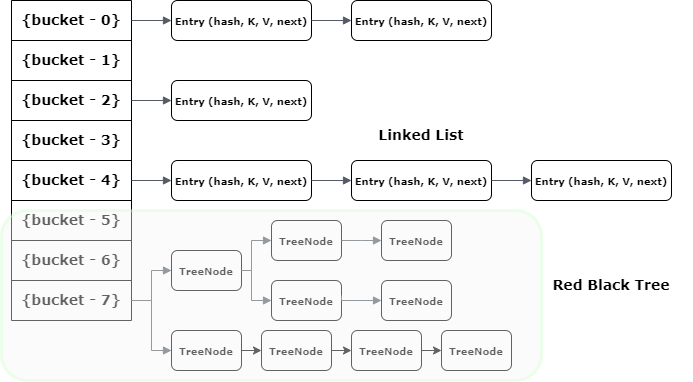
Обратите внимание, что когда узлы в контейнере уменьшаются меньше, чем UNTREEIFY_THRESHOLD, Tree снова преобразуется в LinkedList. Это помогает сбалансировать производительность с использованием памяти, поскольку TreeNodes занимает больше памяти, чем экземпляры Map.Entry. Поэтому Map использует Tree только тогда, когда есть значительный прирост производительности в обмен на потерю памяти.
3. Как хеширование используется для поиска контейнеров?
Хеширование, в своей простейшей форме, является способом назначения уникального кода для любого объекта после применения формулы/алгоритма к его свойствам. Истинная хеш-функция должна возвращать тот же хеш-код каждый раз, когда функция применяется к тем же или равным объектам. Другими словами, два равных объекта должны последовательно выдавать тот же хеш-код.
В Java все объекты наследуют реализацию по умолчанию функции hashCode(), определенную в классе Object. Она создает хэш-код, обычно преобразуя внутренний адрес объекта в целое число, тем самым создавая различные хэш-коды для всех различных объектов.
public class Object {public native int hashCode();}Разработчики Java понимали, что объекты, созданные конечным пользователем, могут не создавать равномерно распределенные хэш-коды, поэтому класс Map внутренне применяет еще один раунд функции хэширования к hashcode() ключа, чтобы сделать их более разумно распределенными.
static final int hash(Object key) {int h;return(key == null) ? 0 :(h = key.hashCode()) ^(h >>> 16);}Это конечный хеш, сгенерированный из начального хеша объекта Key, который является индексом массива, в котором следует искать Node.
4. Операция HashMap.put()
До сих пор мы понимали, что с каждым объектом Java связан уникальный хэш-код, и этот хэш-код используется для определения местоположения контейнера в HashMap, где будет храниться пара ключ-значение.
Прежде чем перейти к реализации метода put(), очень важно узнать, что экземпляры класса Node хранятся в массиве. Каждое местоположение индекса в массиве рассматривается как контейнер:
transient Node<K,V>[] table;
Чтобы сохранить пару ключ-значение, мы вызываем API put() следующим образом:
V put(K key, V value);
API put() внутренне сначала вычисляет начальный хеш с помощью метода key.hashcode(), а затем вычисляет окончательный хеш с помощью метода hash(), рассмотренного в предыдущем разделе.
static final int hash(Object key) {int h;return(key == null) ? 0 :(h = key.hashCode()) ^(h >>> 16);}Это окончательное значение хэша в конечном итоге используется для вычисления индекса в массиве или местоположении контейнера.
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}После того, как контейнер найден, HashMap сохраняет в нем узел.
5. Как разрешаются коллизии в одном ведре?
А теперь перейдем к основной части: поскольку мы знаем, что два неравных объекта могут иметь одинаковое значение хэш-кода, то два разных объекта будут храниться в одном и том же месте массива, называемом контейнером.
Если вы помните, у класса Node был атрибут «next». Этот атрибут всегда указывает на следующий объект в цепочке. Таким образом, все узлы с одинаковыми ключами хранятся в одном индексе массива в виде LinkedList.
Когда объект Node необходимо сохранить в определенном индексе, HashMap проверяет, есть ли уже Node в индексе массива?? Если Node отсутствует, текущий объект Node сохраняется в этом месте. Если объект уже находится в вычисленном индексе, проверяется его атрибут next. Если он равен null, и текущий объект Node становится следующим узлом в LinkedList. Если переменная next не равна null, процесс выполняется до тех пор, пока next не будет оценен как null.
Обратите внимание, что при переборе узлов, если ключи существующего узла и нового узла равны, то значение существующего узла заменяется значением нового узла.
if((e = p.next) == null) {p.next = newNode(hash, key, value, null);break;} Обратите внимание, что если первый узел в контейнере имеет тип TreeNode, то TreeNode.putTreeVal() используется для вставки нового узла в красно-черное дерево.
else if(p instanceof TreeNode)e =((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
Подводя итог, можно сказать, что:
- Если контейнер пуст, узел сохраняется непосредственно в массиве по вычисленному индексу.
- Если ведро не пустое, т.е. узел уже существует, текущий узел проходится в стиле LinkedList до тех пор, пока следующий узел не станет пустым или ключи не совпадут. Как только мы находим, что следующий узел пуст, мы сохраняем текущий узел в конце LinkedList.
6. Операция HashMap.get()
API Map.get() принимает аргумент метода ar ключевого объекта и возвращает связанное значение, если оно найдено в карте.
String val = map.get("key");Аналогично API put(), логика поиска местоположения ведра похожа на API get(). После того, как ведро найдено с использованием конечного значения хеша, проверяется первый узел в местоположении индекса.
Если первый узел имеет тип TreeNode, то для поиска соответствующего объекта ключа используется API TreeNode.getTreeNode(hash, key). Если такой TreeNode найден, возвращается значение.
if(first instanceof TreeNode)return((TreeNode<K,V>)first).getTreeNode(hash, key);
Если первый узел не является TreeNode, то поиск выполняется в режиме LinkedList, и следующий атрибут проверяется в каждой итерации, пока не будет найден соответствующий ключевой объект узла.
do {if(e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k))))return e;} while((e = e.next) != null); 7. Заключение
В этом руководстве по Java обсуждалась внутренняя работа класса HashMap. В нем обсуждалось, как вычисляется хэш в два этапа, и как окончательный хэш затем используется для поиска местоположения контейнера в массиве узлов. Мы также узнали, как разрешаются коллизии в случае дублирующихся ключевых объектов.