Класс Java Hashtable — это реализация структуры данных хэш-таблицы. Он очень похож на HashMap в Java, с самым существенным отличием в том, что Hashtable синхронизирован, а HashMap — нет.
В этом уроке по Hashtable мы изучим его внутреннее устройство, конструкторы, методы, варианты использования и другие важные моменты.
1. Как работает хэш-таблица?
Hashtable внутри содержит сегменты, в которых он хранит пары ключ/значение. Hashtable использует хэш-код ключа, чтобы определить, к какому сегменту должна относиться пара ключ/значение.
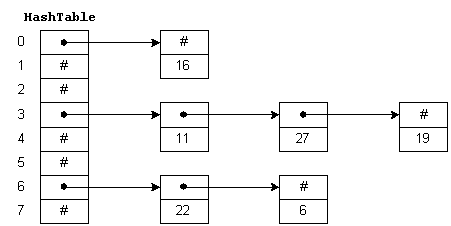
Функция для получения местоположения контейнера из хэш-кода Key называется hash function. Теоретически, hash-функция — это функция, которая при задании ключа генерирует адрес в таблице. Хэш-функция всегда возвращает номер для объекта. Два равных объекта всегда будут иметь одинаковый номер, в то время как два неравных объекта не всегда могут иметь разные номера.
Когда мы помещаем объекты в хэш-таблицу, возможно, что разные объекты(методом equals()) могут иметь одинаковый хэш-код. Это называется коллизией. Для разрешения коллизий хэш-таблица использует массив списков. Пары, сопоставленные с одним контейнером(индекс массива), хранятся в списке, а ссылка на список хранится в индексе массива.
1.1. Декларация хеш-таблицы
Класс Hashtable в Java объявлен следующим образом. Он расширяет класс Dictionary и реализует интерфейсы Map, Cloneable и Serializable. Здесь ‘K’ — тип ключей, а ‘V’ — тип сопоставленных значений с ключами.
public class Hashtable<K,V>extends Dictionary<K,V>implements Map<K,V>, Cloneable, java.io.Serializable{//implementation}
2. Возможности хеш-таблицы
Вот что важно знать о классе Java Hashtable:
- Он похож на HashMap, но синхронизирован, а HashMap не синхронизирован.
- Он не принимает нулевой ключ или значение.
- Дубликаты ключей не принимаются.
- Он хранит пары ключ-значение в структуре данных хэш-таблицы, которая внутри поддерживает массив списка. Каждый список может называться ведром. В случае коллизий пары сохраняются в этом списке.
- Перечислитель в Hashtable не является отказоустойчивым.
3. Конструкторы хеш-таблиц
Класс Hashtable имеет четыре конструктора.
- Hashtable(): Это конструктор по умолчанию. Он создает новую пустую хеш-таблицу с начальной емкостью по умолчанию(11) и коэффициентом загрузки(0,75).
- Hashtable(int size): создает новую пустую хеш-таблицу указанного начального размера.
- Hashtable(int size, float fillRatio): создает новую пустую хеш-таблицу с указанным начальным размером и коэффициентом заполнения.
- Hashtable(Map m): создает хеш-таблицу, которая инициализируется парами ключ-значение из указанной карты.
Обратите внимание, что начальная емкость относится к числу корзин в хеш-таблице. Оптимальное число корзин требуется для хранения пар ключ-значение с минимальным количеством коллизий(для повышения производительности) и эффективного использования памяти.
Коэффициент заполнения определяет, насколько полной может быть хеш-таблица, прежде чем ее емкость увеличится. Его значение лежит в диапазоне от 0,0 до 1,0.
4. Методы хеш-таблиц
Методы в классе Hashtable очень похожи на HashMap. Посмотрите.
- void clear() : используется для удаления всех пар в хеш-таблице.
- boolean contains(Object value) : возвращает true, если указанное значение существует в хэш-таблице для любой пары, в противном случае возвращает false. Обратите внимание, что этот метод идентичен по функциональности функции containsValue().
- boolean containsValue(Object value) : возвращает true, если указанное значение существует в хэш-таблице для любой пары, в противном случае возвращает false.
- boolean containsKey(Object key) : возвращает true, если указанный ключ существует в хэш-таблице для любой пары, в противном случае возвращает false.
- boolean isEmpty() : возвращает true, если хеш-таблица пуста; возвращает false, если она содержит хотя бы один ключ.
- void rehash() : используется для увеличения размера хеш-таблицы и перехеширует все ее ключи.
- Object get(Object key) : возвращает значение, с которым сопоставлен указанный ключ. Возвращает null, если такой ключ не найден.
- Object put(Object key, Object value) : сопоставляет указанный ключ с указанным значением в этой хеш-таблице. Ни ключ, ни значение не могут быть нулевыми.
- Object remove(Object key): удаляет ключ(и соответствующее ему значение) из хеш-таблицы.
- int size() : возвращает количество записей в хэш-таблице.
5. Пример хеш-таблицы
Давайте рассмотрим пример использования Hashtable в программах Java.
import java.util.Hashtable;import java.util.Iterator;public class HashtableExample{public static void main(String[] args){//1. Create HashtableHashtable<Integer, String> hashtable = new Hashtable<>();//2. Add mappings to hashtablehashtable.put(1, "A");hashtable.put(2, "B" );hashtable.put(3, "C");System.out.println(hashtable);//3. Get a mapping by keyString value = hashtable.get(1); //ASystem.out.println(value);//4. Remove a mappinghashtable.remove(3); //3 is deleted//5. Iterate over mappingsIterator<Integer> itr = hashtable.keySet().iterator();while(itr.hasNext()){Integer key = itr.next();String mappedValue = hashtable.get(key);System.out.println("Key: " + key + ", Value: " + mappedValue);}}}Вывод программы.
{3=C, 2=B, 1=A}AKey: 2, Value: BKey: 1, Value: A
6. Производительность хеш-таблицы
С точки зрения производительности HashMap выполняет O(log(n)) по сравнению с O(n) в Hashtable для большинства распространенных операций, таких как get(), put(), contains() и т. д.
Наивный подход к потокобезопасности в Hashtable(«синхронизация каждого метода») делает его намного хуже для потоковых приложений. Нам лучше синхронизировать HashMap извне. Хорошо продуманный дизайн будет работать намного лучше, чем Hashtable.
Hashtable устарел. Лучше всего использовать класс ConcurrentHashMap, который обеспечивает гораздо более высокую степень параллелизма.
7. Hashtable против HashMap
Давайте быстро перечислим различия между хэш-картой и хэш-таблицей в Java.
- HashMap не синхронизирован. Hashtable синхронизирован.
- HashMap допускает один нулевой ключ и несколько нулевых значений. Hashtable не допускает нулевых ключей или значений.
- HashMap быстрый. Hashtable медленный из-за дополнительной синхронизации.
- HashMap обходит Iterator. Hashtable обходит Enumerator и Iterator.
- Итератор в HashMap является отказоустойчивым. Перечислитель в Hashtable не является отказоустойчивым.
- HashMap наследует класс AbstractMap. Hashtable наследует класс Dictionary.
8. Заключение
В этом уроке мы узнали о классе Java Hashtable, его конструкторах, методах, реальных вариантах использования и сравнили их производительность. Мы также узнали, чем hastable отличается от hashmap в Java.
Не используйте Hashtable в новых приложениях. Используйте HashMap, если вам не нужна параллельная обработка. В конкурентной среде предпочтительнее использовать ConcurrentHashMap.
Пишите мне свои вопросы в комментариях.
Ссылка: