Научитесь повышать производительность ConcurrentHashMap путем разумной оптимизации аргументов конструктора.
1. Класс ConcurrentHashMap
ConcurrentHashMap очень похож на класс HashMap, за исключением того, что ConcurrentHashMap предлагает внутренне поддерживаемый параллелизм. Это означает, что нам не нужны синхронизированные блоки при доступе к его парам ключ-значение в многопоточном приложении.
//Initialize ConcurrentHashMap instanceConcurrentHashMap<String, Integer> m = new ConcurrentHashMap<>();//Print all values stored in ConcurrentHashMap instancefor each(Entry<String, Integer> e : m.entrySet()){system.out.println(e.getKey()+"="+e.getValue());}Код выше является обоснованно допустимым в многопоточной среде приложения. Причина, по которой я говорю «обоснованно допустимым», заключается в том, что код выше обеспечивает потокобезопасность, но все же может снизить производительность приложения. И ConcurrentHashMap был введен для повышения производительности при обеспечении потокобезопасности, верно??
Так что же мы здесь упускаем?
2. Конструктор по умолчанию и аргументы
Чтобы понять это, нам нужно понять внутреннюю работу класса ConcurrentHashMap. И лучше всего начать с рассмотрения аргументов конструктора. Полностью параметризованный конструктор ConcurrentHashMap принимает 3 параметра:
- начальнаяемкость
- Коэффициент нагрузки
- concurrencyLevel
Первые два аргумента довольно просты, как следует из их названия, но последний — хитрый. concurrencyLevel обозначает количество шардов. Он используется для внутреннего разделения ConcurrentHashMap на это количество разделов, и создается равное количество потоков для поддержания безопасности потоков на уровне шарда.
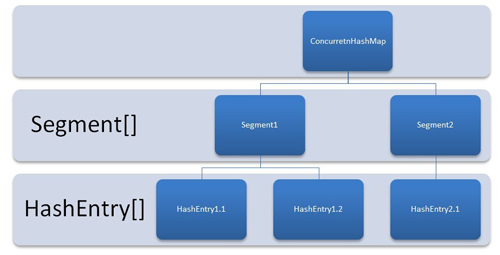
Значение «concurrencyLevel» по умолчанию равно 16.
- Это означает 16 сегментов всякий раз, когда мы создаем экземпляр ConcurrentHashMap с помощью конструктора по умолчанию, даже до добавления первой пары ключ-значение.
- Это также означает создание экземпляров для различных внутренних классов, таких как ConcurrentHashMap$Segment, ConcurrentHashMap$HashEntry[] и ReentrantLock$NonfairSync.
В большинстве случаев в обычных приложениях один шард способен обрабатывать несколько потоков с разумным количеством пар ключ-значение. И производительность также будет оптимальной. Наличие нескольких шардов просто усложняет все изнутри и вводит много ненужных объектов для сборки мусора, и все это без улучшения производительности.
Дополнительные объекты, создаваемые на одну параллельную хэш-карту с использованием конструктора по умолчанию, обычно находятся в соотношении 1 к 50, т.е. для 100 таких экземпляров ConcurrentHashMap будет создано 5000 дополнительных объектов.
3. Рекомендуемая инициализация
На основании вышеприведенного анализа я предлагаю разумно использовать параметры конструктора, чтобы сократить количество ненужных объектов и улучшить производительность карты.
Хорошим подходом может быть такая инициализация:
ConcurrentHashMap<String, Integer> instance = new ConcurrentHashMap<String, Integer>(16, 0.9f, 1);
- Начальная емкость 16 гарантирует достаточно большое количество элементов до изменения размера.
- Коэффициент загрузки 0,9 обеспечивает плотную упаковку внутри ConcurrentHashMap, что оптимизирует использование памяти.
- А уровень параллелизма, установленный на 1, гарантирует, что будет создан и поддержан только один шард.
Обратите внимание, что если вы работаете над очень высококонкурентным приложением с очень высокой частотой обновлений в ConcurrentHashMap, вам следует рассмотреть возможность увеличения уровня параллелизма более чем на 1, но, опять же, это должно быть хорошо рассчитанное число, чтобы получить наилучшие результаты.